Not exactly, because actually measuring the load of something takes some processing, so some of the 4% is just the measuring itself. The rest is a combination of iterating through the modules and calling their processing functions (even if the processing just returns back right away). To do a better test of this low end, we’d need to raise the module limit and then see how many blanks we can add before it hits 99%. That will make the measurement effects less pronounced.
We can actually raise this, it’s not (directly) related to CPU but rather to memory used for running the patch.
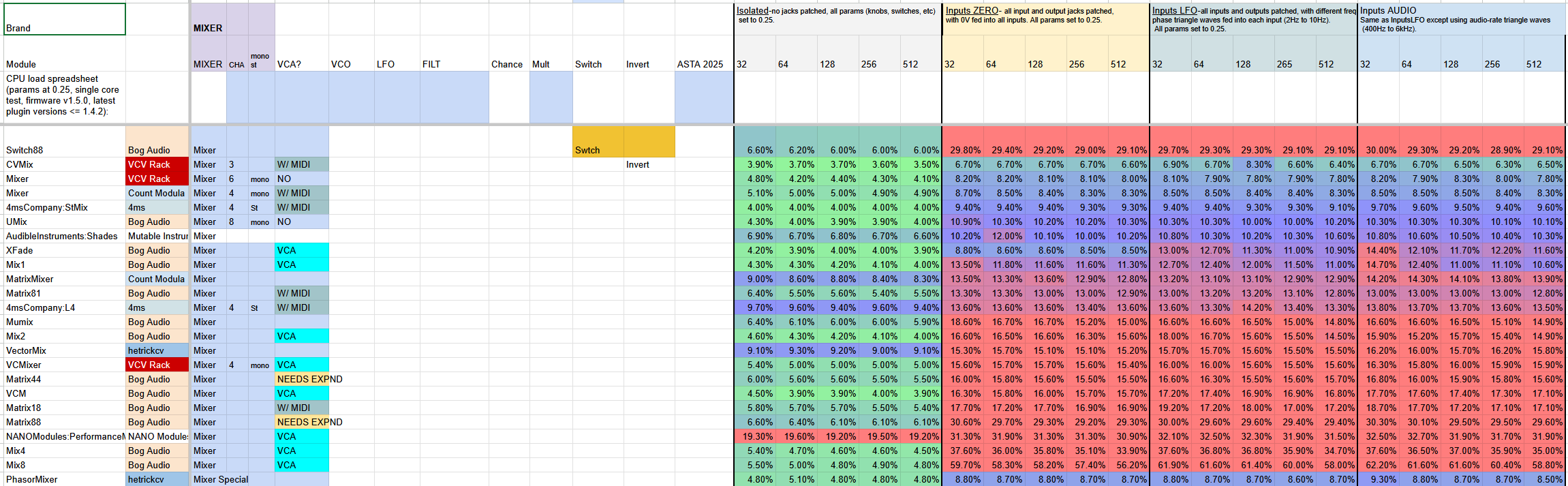
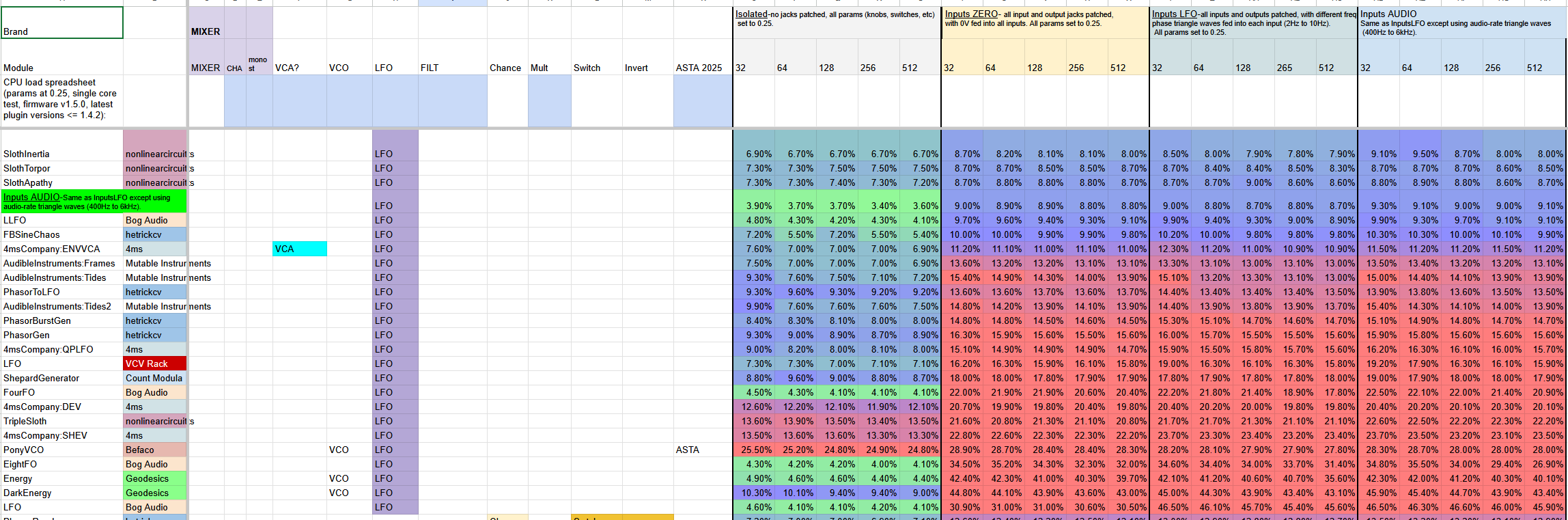
Excellent! Thanks for doing this. I’m happy to see the HCV and NLC modules are generally pretty low. Scanner and Rotator could afford some optimization. Data Compander was the shocker, but there’s not much to optimize there without replacing some of the math functions with lookup tables.
The one that really jumps out at me is the difference between Phasor Gates, Phasor Gates 32, and Phasor Gates 64. The code between them is pretty much identical except for the interface.
My guess is that this block of code is the culprit:
// Gate buttons
for (int i = 0; i < NUM_STEPS; i++)
{
if (gateTriggers[i].process(params[GATE_PARAMS + i].getValue())) {
gates[i] ^= true;
}
lights[GATE_LIGHTS + 3 * i + 0].setBrightness(i >= stepsKnob); //red
lights[GATE_LIGHTS + 3 * i + 1].setBrightness(gates[i]); //green
lights[GATE_LIGHTS + 3 * i + 2].setSmoothBrightness(isPlaying && lightIndex == i, args.sampleTime); //blue
}
Either gateTrigger is more expensive than I thought, or maybe setSmoothBrightness is causing the hit.
Yep, I profiled it by flipping GPIO pins. For the PhasorGates64, that loop takes about 3.4us, which is 16.3% of a sample frame at 48kHz.
Just to see, I tried changing the setSmoothBrightness to plain setBrightness and the time for that loop dropped to 2.2us. But the display is not as good at higher speed phasors.
Converting bool to float is trivial, but it’s still a handful of operations. Maybe pre-computing that would help (i.e. compute the red color for all LEDs only when the stepsKnob value changes.)
Also, I don’t know if this is realistic but there might be some potential for vectorization here since it’s the same operations repeated.
Or, perhaps the lights can be updated only once every block. The GUI won’t use any values that the audio loop sets until it’s done with a block. Min block size is 32 (but you could do 16 to be future-proof), that would save a lot.
Edit: another thought: the results of the calculations in setSmoothBrightness aren’t used until the end of a block (min 16 or 32). So that would be an easy win with no change to the visual response: to calculate that once per block instead of per frame (adjusting the coefficients so that it gives the same value as if it were called 16 or 32 times)
Let me try this again. I am going too many directions.
As the library of available modules expands… It might be helpful to have pops ups or some sort of a resource to save CPU along side any CPU estimator related to the modules that are active in the patch and included in the calculation…
For example, many of the tips in here on modules that either have others that are better if using multiple VCAs, or if there is an internal setting that makes a module much more CPU friendly, or a limit where it turns into a CPU hog. I could see this as a companion module that one could have next to the Meta Module- so it is easy to not have it taking up screen space, and use notes compiled in a wiki from the community here, so the 4MS team is not the ones doing the work of compiling- heck a 3rd party app developer could write the code, I sadly don’t have that skill set.
Actually, any sort of wiki that has a module by module tip set would be helpful- even if it is only hosted here on the 4MS webpage. Modules that are not used much would simply not get much community attention and edits.
Many people want to know how a VCV patch’s CPU use translates to MM’s load.
A friend had a cool idea:
What if you could run VCV in a virtual machine that emulated whatever CPU comes closest to the MM’s processing power? (I’m assuming you can’t emulate the same processor MM uses, only Intel, etc types, but maybe I’m wrong about that).
that’d not work… as a CPU close (or even same as MM) could never run vcv desktop, mainly due to UI. (which is why 4ms didnt try to run the vcv code on mm)
I ran vcv desktop on an A17, which is much more power than the A7/M4 combo in the MM, and it didn’t have enough ‘spare’ dsp to run the patches the MM can.
at least that was my ‘feeling’, but the UI was too sluggish for me to want to try too much.. so I kind of gave up on that approach.
if you really wanted to do this ‘emulation’ route,
the best route would be to run VCV rack as ‘normal’ on a powerful desktop.
but then fake the the cpu load numbers reported, by scaling.
… it’d not be 100% accurate (far from it), but might given an idea.
but honestly, I think this ‘cpu load’ approach is a bit of a red-herring…
you get a feel for whats possible after using the MM for a while.
I think the better approach, would be too look at the broader picture…
how can you streamline vcv → mm patch development?
for me this would be some kind of (potentially fake) live patching.
streamline the transferring of patch to the MM, then get the MM to report back the real cpu numbers back into the MM ‘hub’ within vcv.
this would make the upcoming wifi expander module much more desirable.
one suggestion to make this even more powerful…
(and I am saying this as “I would be willing to help put some time towards this in the coming weeks” if others in the community would find this helpful, if that helps the 4ms team out. maybe others could kick in)
Adding columns for module type so we can sort by CPU load by module type quickly.
… if Column V is VCA, and if a module qualifies, put an X. Column W could be Filter. etc. There is a sweet spot of course, but I would probably start with the VCV rack groupings.
A really quick sort for VCAs , Delays, etc. when patch building and hitting that CPU shutdown would be VERY helpful!
Looking forward to seeing everyone at Namm or Buchela and friends- where ever you end up!
Not done yet, but a start for patches I am building. a quick sort by CPU and then sort by Module type is very helpful for eliminating options quickly, or finding options on the fly.