I wrote some code to measure CPU load for every module under various conditions. I have the raw results here.
Goals
The goal is to create some new features on the MM hardware and in VCV that leverage pre-recorded CPU load data to make a reasonable estimate of CPU usage of a patch. For example, the MM firmware could tell you in real-time how much the CPU usage would change if you added a certain module. Or to be able to browse modules and choose the lowest CPU utilizer that does the function you need. Or when using VCV Rack, to display the estimated CPU usage if you were to run the patch on MM.
Test Data
I offer this up for comments, suggestions, and review. This is not the be-all-end-all source of cpu load numbers. This is just part of the CPU load picture. I will be continuing working on this and I will upload new improved data and/or new test conditions without warning! So, if you can handle some work-in-progress data, then please read on:
Updated Dec 4, 2024:
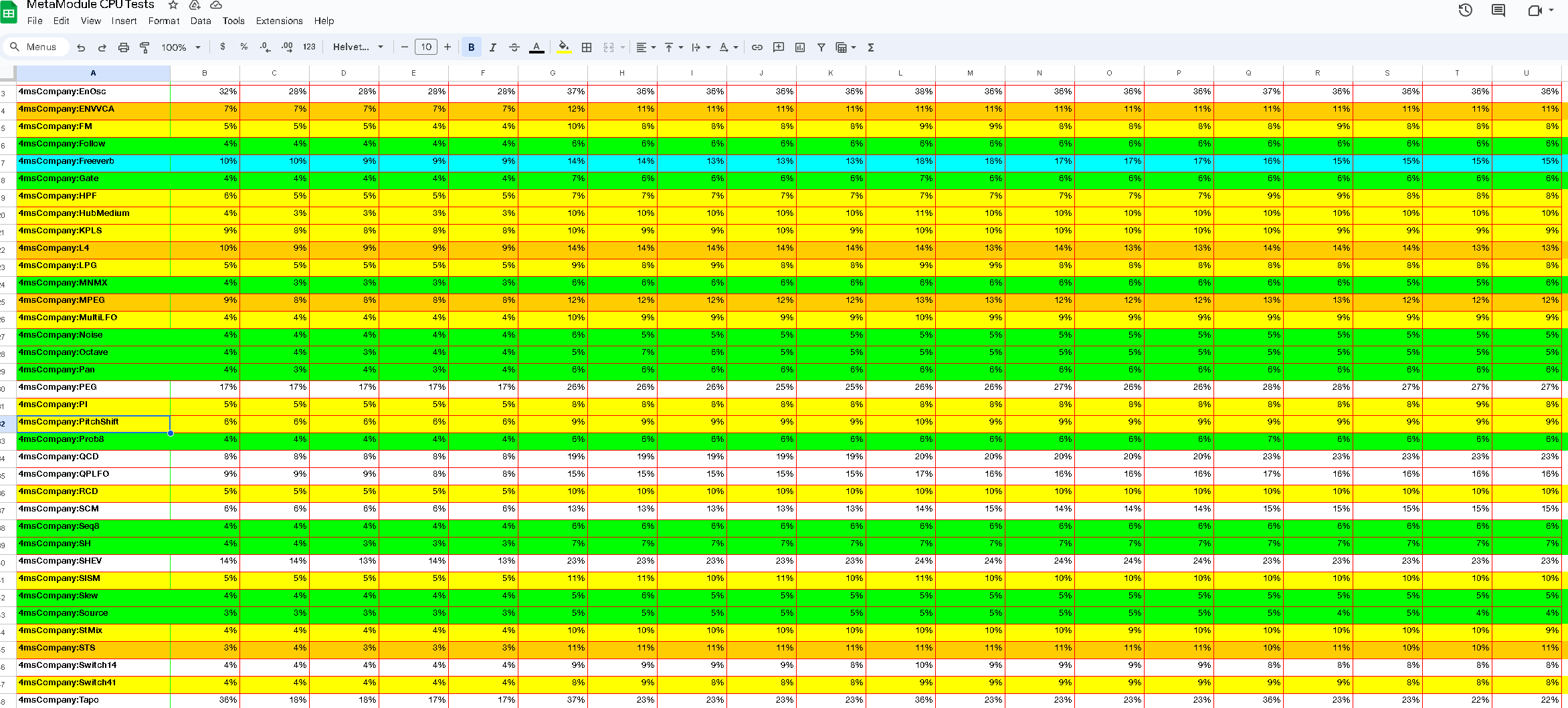
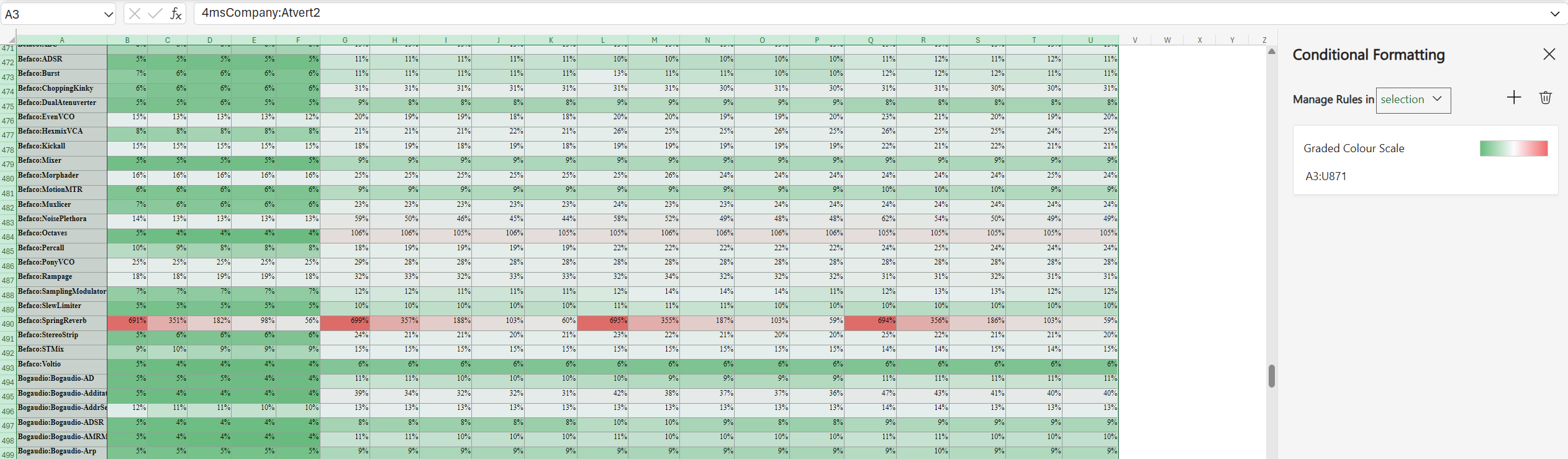
CPU load spreadsheet (params at 0.25, single core test, firmware v1.5.0, latest plugin versions <= 1.4.2):
Updated April 4, 2025:
v2.0-dev test results:
In the spreadsheet you will see five columns (one for each block size) for each of the four tests:
- Isolated: no jacks patched, all params (knobs, switches, etc) set to 0.25.
- InputsZero: all input and output jacks patched, with 0V fed into all inputs. All params set to 0.25.
- InputsLFOs: all inputs and outputs patched, with different frequency+phase triangle waves fed into each input (2Hz to 10Hz). All params set to 0.25.
- InputsAudio: Same as InputsLFO except using audio-rate triangle waves (400Hz to 6kHz).
Conditions of the tests
I tested all built-in and plugin-in modules at each block size (32, 64, 128, 256, 512). For each module, the test procedure automatically created a patch with just the module-under-test. To handle Bogaudio modules, the modules were told to process one audio frame, and the timing of this was thrown out. Then the module was “run” 2048 times and the amount of time it took to process each audio frame was recorded. The worst-case time to process each block was recorded, and this number is divided by the block size to provide a worst-case average time to process a sample. Divide this by the amount of time we have per sample (20.8333us for 48kHz) and you get the CPU load for the module under the test conditions.
In between each time the module processes a sample, the code set and/or modulated the module params and inputs depending on which test was being run (see above descriptions of each test).
My reasoning to use 0.25 for the param values is that some buttons act like you are long-holding them if we set 0.5, and things like sliders might disable a channel if set to 0.
Interpreting the results
The number in each cell is the percent load for ONE CPU CORE at 48kHz.
There are two CPU cores. Each CPU core runs in parallel so you basically get to add up to 100% twice before the MM reports “CPU usage > 99%”.
It might be tempting to mentally divide the load percentage number in half… but, I think that’s a bit misleading. For example if you have a module with 60% load, you could run two of them (60% on each core). But adding a third would mean one core is 120% and that’s not allowed (but dividing by 2 would mean you think of 60% as 30% which implies you can have 3 x 30% = 90%).
Both cores have to be done before the audio processing is done. So if one core is at 50% and the other core is at 75%, then it’s no different than if both cores were at 75%.
There currently is no load-balancer so it’s possible to have a patch where one core is at 90% and the other is at 5%.
Beyond the module usage, each cable between modules adds a tiny bit of load. Also each knob mapping in the active knob set adds a tiny bit of load.
Obviously none of these tests are going to represent typical usage (that is to say, in most patches we don’t have ALL the jacks on ALL the modules being audio-rate modulated, nor do we have NONE of the jacks patched) – but it’s probably safe to say that whatever your patch looks like, it’s somewhere between the two extremes.
Predicting CPU usage is extremely complex as all the modules and the two CPU cores plus the various levels of memory cache and CPU buses all interact to produce one single percentage. As much as it would be awesome to say “I’m using modules A, B, and C, so I’ll just add up three numbers that will be my exact CPU load”, it’s not going to be that easy. This is modular: we like to make complex webs of patch cables and experiment with unorthodox signal flows, and it’s not a simple thing to predict what will happen. Which is part of the fun, too.
Possible improvements to the tests
More Tests:
- Another test we could do is modulate all the params and see how that effects CPU load.
- Another set of tests could be using white noise into all the jacks.
- Another set of tests could be done by modulating a single input, or a single knob at time
Running the tests differently:
- The tests could be run multiple times, in random orders to weed out bus or cache delays
- A patch with lots of modules could be automatically created and run, but only the time taken for the module-under-test would be recorded. This would more realistically simulate how the cache would be loaded in real-world patches.
- The way I do it now, I’m running the module 2048 times for each block size. A better way would be to run it 2048 and then group it into block sizes, then repeat that 5 times and report the worst-case.
- Integrate the tests into a HIL (hardware-in-the-loop) test that runs automatically for each firmware and plugin release, updating the database and flagging any drastic changes in load.