They are much more CPU-heavy than other similar modules. Could this be fixed by turning off some functionality or via code optimization?

I found the ‘simple’ modules are pretty light, its just the more complex ones.
but you’d have to get much more specific to answer this question, i.e. A/B comparison.
for some, they are functionally different, and this can be more expensive in cpu. e.g. if you are doing analog modelling or similar.
in other cases, its optimisation e.g. they don’t use simd where an alternate might.
e.g. bare in mind the Mutable Instrument has a huge amount of optimisation in them, as some were created for very limited hardware (things like the STM32F4)
so I think its a case by case example, rather than a general case of 4ms modules being heavier than others.
I think in fairness, given the amount 4ms have on their plate developing the firmware for the MM, probably its time better spent (at present) on providing that platform, rather than optimising some their modules esp where we have 3rd party alternatives.
I understand what you are saying. I am just looking for an explanation. I would have thought they would be more efficient because they are developed as native MM apps. But, the high CPU is also evident on MM itself. Perhaps @danngreen can provide some insight.
dann kind of talked about this previously on your other topic.
the vcv wrapper is pretty darn good, so native plugins dont get much of an improvement.
Id suspect also where it is an improvement, it’ll be more on the UI core rather than the dsp cores which is what you are focused on here.
really, the dsp side is much more affected by the algos you use, how you use the fpu and simd, rather than if its a native mm plugin or not.
Id be surprised if there is any generic reason that the 4ms modules use a bit more dsp cpu than others… other than perhaps, 4ms are spinning more plates, and so cannot focus solely on these MM modules as much as other devs can on particular modules.
1 Like
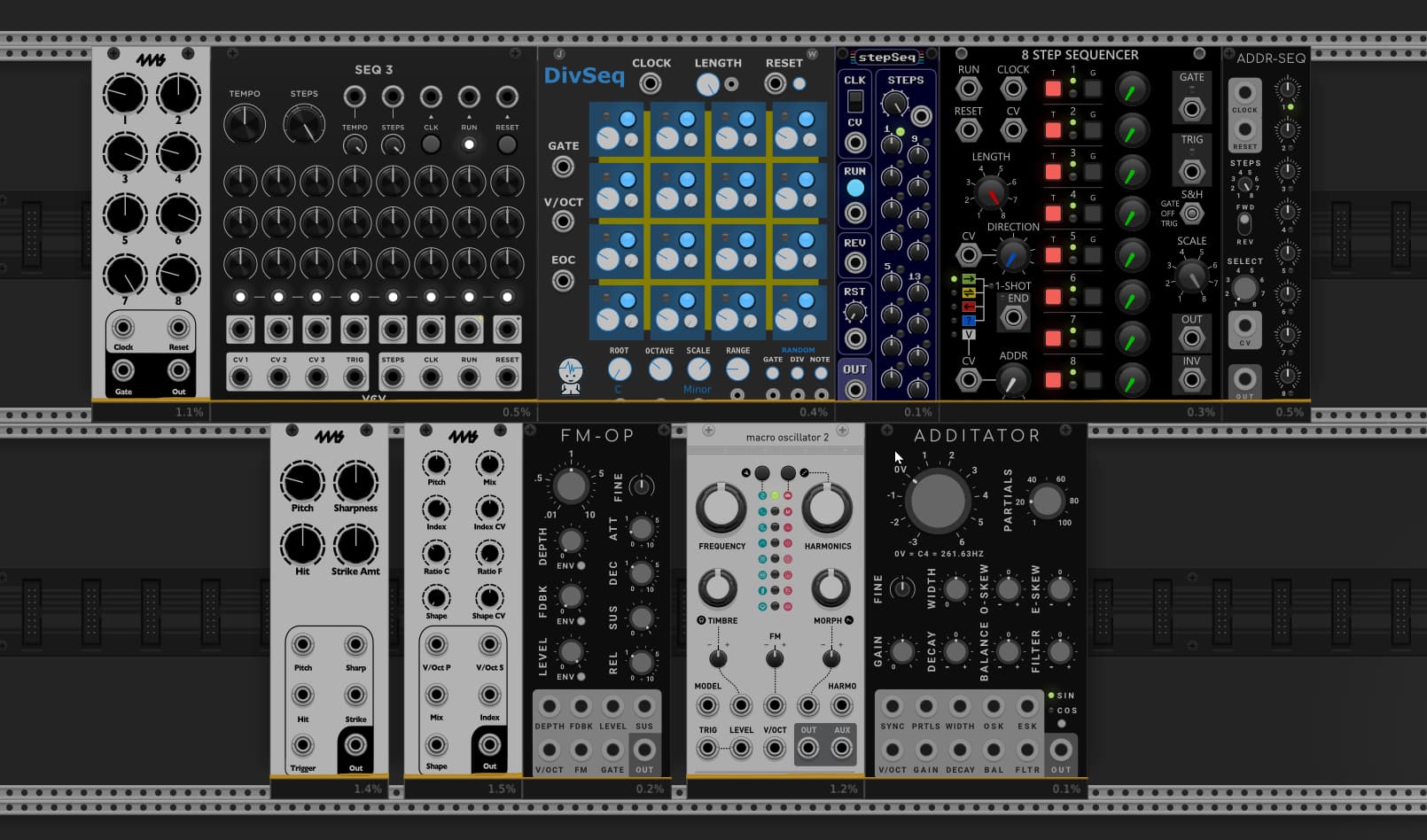
They are very capable modules, however they are very CPU intensive in most cases. That limits my ability to use them in patches. The ones I have shown above in the screen grab maxed out the MMs CPU before they were even patched.
I’m going to guess you’re getting the perception that the CPU is high for the group of modules you picked because there are a few modules in there that use a lot of CPU but have no equivalent in other brands. That is to say, some 4ms modules definitely use a lot of CPU, but they do something no other modules does.
For example, take the the EnOsc. You might think it has high CPU usage since it uses around 30%-34% and other VCOs will make a sine wave using much less CPU. But keep in mind the EnOsc is really 16 oscillators, each of which is crossfading between two frequencies (so it’s running 32 oscillators at all times), plus waveshaping, distortion and cross-FM abilities. Creating that from 16 or 32 single-channel VCOs would consume much more than the EnOsc. If you only need a simple sine wave, then the EnOsc is overkill of course. But if you harness its potential in a patch, then only using 30% CPU is amazing.
I think if you look at the CPU load table of numbers you’ll find that each 4ms module performs equally or sometimes better than other modules that do the same thing. Look at the entry for each in the spreadsheet and compare to something that does a similar function, you’ll see they are about the same as other modules, or sometimes more efficient. E.g. the 4ms StMix uses 5-9%, which is equal or less than any other 4-channel mixer (even just mono mixers, let alone stereo). The Freeverb (which uses SIMD) is perhaps the lightest reverb available for the MM. The EnvVCA is maybe the lightest ways to get an LFO (or AD envelope) and a VCA. There are a lot of new plugins lately so I might be missing something that just popped up.
This is not to say the modules here are perfect: we could certainly do another round of optimizations. If there is a particular module you find to be higher than others in its category, I would take time to improve it, so let me know if there is a specific example. Some of the lesser-used modules in the hardware world like the PI and QPLFO, we didn’t try too hard to optimize since we didn’t expect them to be used much (but if I’m wrong, then I can give it a shot to improve them!). I do have an open issue on our github to see if I can improve EnOsc performance using NEON SIMD.
Looking at the screenshot you have, the Tapo and DLD are probably the highest CPU users besides the EnOsc. The Tapo runs around 20% if you have block size 32 or higher. Kind of a lot, but it does something no other module does, so there’s nothing really to compare it to. The DLD uses max 25-27%, which is high, but not bad for crossfading delays. Compare to the Fundamental Delay (which I think is the lightest delay??), it uses 1-2% more, but on the other hand the DLD has a lot more features, and is two independent delay channels.
Regarding virtual modules compared to hardware, the efficiency is about what we’d expect. On the hardware EnOsc, it consumes at 99% of the CPU of a 216MHz M7 chip. So on a dual-core 800MHz platform you might expect to run 7 or so EnOsc. In reality we can run 6 of them because there is an extra bit of inefficiency in not being able to hardwire physical pots and jacks to the parameters – basically the ability to make knob and jack maps and change them on the fly adds a bit of overhead to all patches on the MetaModule. Some of this is in the MM engine itself, and some of it is in the adaptor layer we made for the EnOsc to create a virtual hardware layer.
1 Like
Hey @danngreen:
Thank you very much for your long and very detailed response.
I certainly agree that modules like Tapo, DLD, and EnOsc are one-of-a-kind modules and I can see why they would use so much computing power.
I was wondering about some of the more “pedestrian” modules.
On my system, the CPU numbers displayed in VCV are somewhere between 1/7 to 1/8 of the value I see in MM. So, a module that uses 1% in VCV would be somewhere around 7-8% in MM in my case.
I posted below comparisons between two categories I use a lot: Sequencers and Sound Modules.
There is a pretty big difference between 4ms modules and the other ones I would consider using in their place with the sole exception of MacroOsc2, and that module is one of a kind because of how much sonic potential it has.
since our laptop’s processors/os’s are really different than the mm’s, we’ll simply never get %’s in vcv that match what we see in mm. some modules will always just behave differently, cpu wise, between mm and the pcs. however i was able to get pretty darn close w the mm and my:
asus vivobook (e210ma, w 2core n4020)- setting cpu to “0%” in windows11 power profile
windows lets you throttle the cpu which is v useful in this case. so if i keep my patches in vcv on the asus running max cpu %80 use, they always just work great on the mm (typically running between 80-90% on mm). that has helped make building patches for the mm go so much faster+smoother!
There’s a big difference between saying MM modules are “CPU heavy” and essentially saying that MM doesn’t have the same power as your laptop.
you’ll have to look into details of each, to see if they are really similar…
let’s look at one, as an example…
FM OP vs 4ms FM
these are not equivalent. the 4ms FM is actually a 2 op oscillator, as it has both a fundamental and carrier, whereas FM OP is a single op, its used as a building block to build N op fm.
also, it has only sine rather than being able to have its shape altered.
also fm op (like many other modules) optimises based on having its IO patched. this is not uncommon. 4ms fm does not appear to do this.
so… if you take all this into account, and use 2 FM OP patched up, then its similar to cpu used by 4ms fm … .at least in my simple test.
plaits would be more similar, as its fm engine is 2 op.
but as I mentioned previously, MI is highly optimised.
however, its another reason , as others have mentioned comparing on a PC is not really comparable…
MI code is largely unoptimised on a laptop, its compiled with a TEST macro, which MI solely used for functional testing.
(you don’t really notice this on a laptop, because a laptop has so much cpu compared to the hardware it was designed for)
again, probably MI modules are a corner case, but some other hardware emulations may be similar.
i say the more mm module optimizations the merrier! and if that means that the patch that runs at 80% in vcv on my quasi-mm-parity asus laptop setup, then runs <80% on mm, well all the better.
I see, I misunderstood your original statement – I thought you meant CPU heavy on the MetaModule, but you meant CPU heavy on your desktop in VCV Rack.
Besides what’s been said already, I would also add that we took efforts to optimize the modules for the 32-bit Cortex-A7 architecture, and made no special effort to optimize for desktop computers. Basically, the goal of the 4ms modules was to have them run on the MM, so that’s what we targeted. The 4ms modules are CoreModules (aka “native MetaModule”) and there’s a VCV Rack adapter layer that lets them build and run as VCV Rack plugins. If we later wanted to target another plugin format, we would only need to create an adapter layer for that and it would (should) run. So they’re specifically NOT optimized for VCV Rack in particular. The power of a desktop is so far greater than an embedded system so it makes a lot of sense to do it this way.
1 Like
I’m sure that I’m not the only MM user who would rather see Dan & the 4ms crew spend their time working toward the V2.0 general release vs carving out time to provide detailed answers to arcane inquiries that mean little to the broader community.
1 Like
What I was trying to say is that I found the differential between my computer’s CPU and the processor in the MM through testing. It is between 7-8X faster the way I have VCV set up. (YMMV) That makes it easy for me to develop patches in VCV and determine how they would perform in the MM. As a result, I have been able to build patches with 20+ modules that run great on the MM.
No, I meant CPU heavy on the MM. Based on tests, I have determined that the way I have VCV set up on my PC, it is 7-8X faster than MM. That makes it pretty easy to tell how each module will perform in MM. When developing patches in VCV for MM, I try to look for modules that will use less than .5% in VCV on my PC. As a result, I have been able to build patches with 20+ modules that use less than 40% of the MM CPU when unpatched.
We are very close to 2.0 general release. I am not asking for resources to be diverted. I was just asking a question. BTW, I have been very active in beta testing 2.0.
I compare on VCV so I can develop large patches that I can be assured to run well on MM. As I stated several times, the way I have VCV installed on my PC, it is 7-8X more powerful than MM. That allows me to just multiply the total unpatched config and that will give me a good indication of how much CPU it will take up on the MM in an unpatched state. As I stated, I have been able to build patches with 20+ modules that take up less than 40% of the CPU in MM. Even when fully patched, they run well (at usually somewhere between 50%-60% CPU on the MM). This is very important in my use case because the MM is the primary module in my rack. The is interesting to know about 4ms FM vs. FM OP. (BTW, I generally uncheck anti-alias feedback and external FM in FM OP because that increases CPU a lot).
very interesting info! im curious: by other plugin formats do you mean something like arm lv2/vst plugins (running along side the vcv modules?)?
I think that CLAP would be an intriguing possibility for MM since it is open source. Not sure what modules would be able to run, however. GitHub - free-audio/clap: Audio Plugin API